-

Just Because
-

NOC Runnaversary
Kat and I met at the Fullsteam Run Club in Durham on June 3rd. That makes this our runnaversary. We try to do something outdoorsy in spirit of this tradition. The most recent trip was the Nanthahala Outdoor Center for rafting and mountain biking. We had an excellent time as you can see from the…
-

Becoming Anti-social
This isn’t about becoming anti-social in the traditional sense, but more anti-social media. Asocial would be a more accurate term. A few years back I made a decision to disconnect from most social media platforms. If you wanted to get in touch with me or know what I was doing, you would have to see…
-
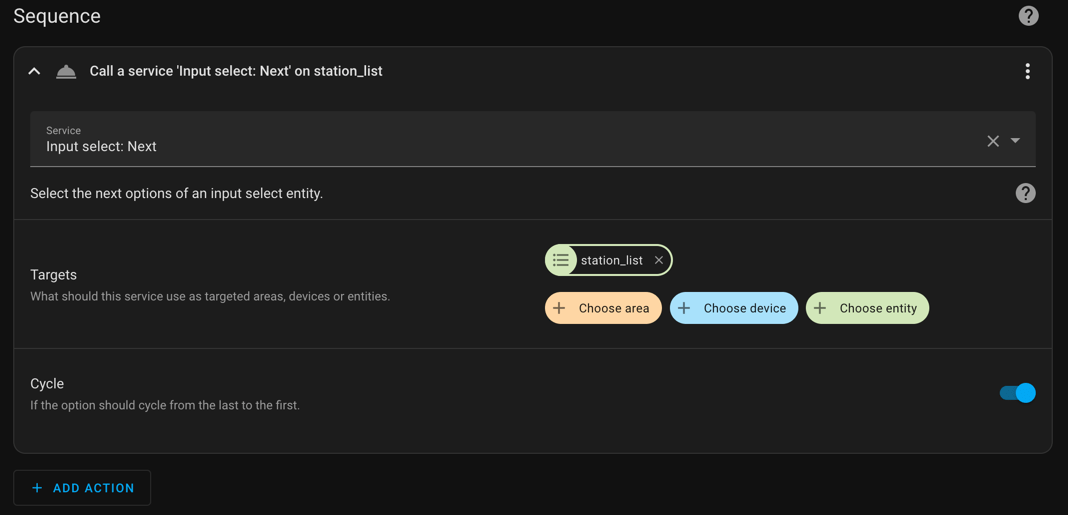
Random Playlist Selector with Sonos and Home Assistant
Here’s something different for the blog. I’ve taken some inspiration from the HashiCorp RFC and am tracking my personal project that way. I find it useful. Problem Statement I get tired of listening to the same playlist too often. I also want to reduce the number of choices I need to make in the day.…
-
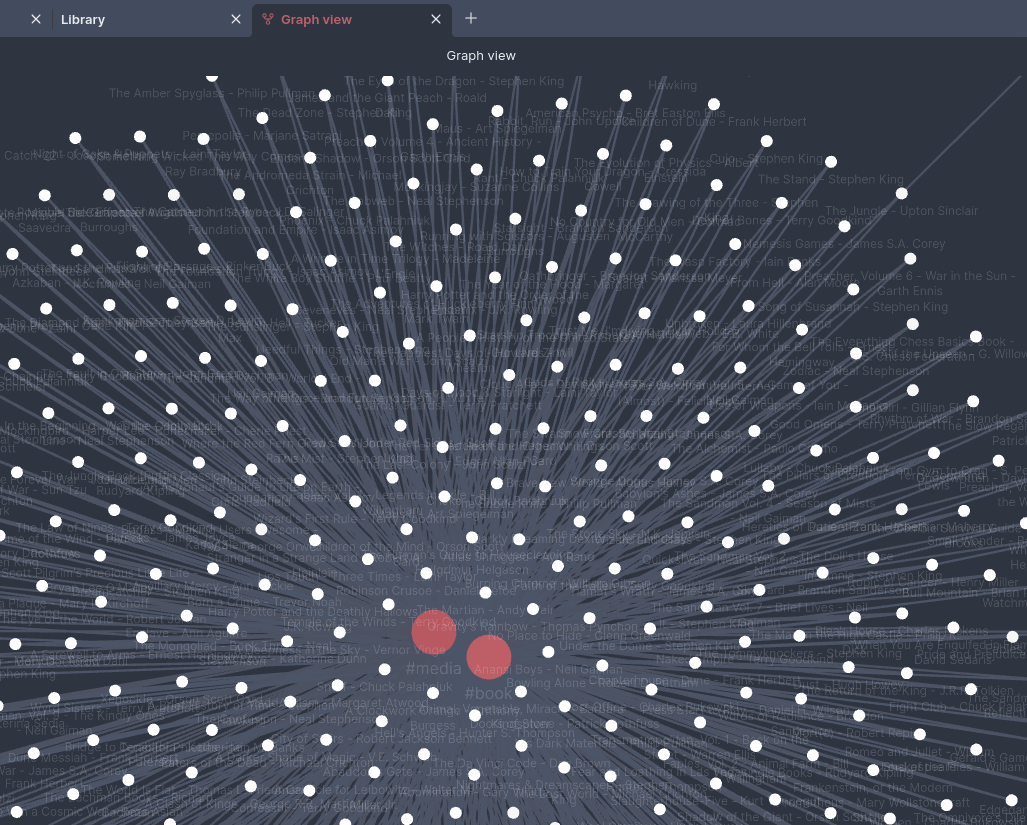
Converting from Goodreads to Obsidian
Last month I got an idea that I’d like to do book reviews in my Obsidian note taking vault. This would satisfy a few problems I’ve had: There were GREAT plugins available like the Obsidian Book Search plugin. However, there wasn’t anything that would take my 400+ books with review text, rating, date read, and…
-

nftables!?
Apparently while I was busy working on some other things, the world switched to nftables and no one told me. I logged into my Linux web server the other day and realized the firewall rule set that had been hand crafted with iptables probably a decade or more ago is now completely gone. It probably…
-

Should I Write About Nutanix Community Edition?
Would there be any interest if I made some articles or videos about Nutanix Community Edition? Right now all of the main info for it is captured in the Nutanix NEXT Community Forums. I see that Nutanix CE and the new CE 2.0 are really popular search terms. What would y’all be interested in? Would…
-

The Kentucky Derby
Kat has a bucket-list item to go to The Kentucky Derby – so now we’re going next week! My biggest tasks are to: I’ve never been to a horse race before, so I’ve got a little bit of imposter syndrome here. Someone asked me “Oh, so you’ve been before?” How do you tell them, “No,…
-

Obsidian for Tasks and Lowering Blood Pressure
I started creating tasks in Obsidian using the tasks plugin and at first it was amazing. It really helped me lower my stress levels because I knew that I could just write something down in my notes and Obsidian would remember it for me. I could quickly scan through my task list and make sure…
-

Obsidian for Notes
I’ve been using Obsidian to take notes and track all the action items in my life. I’ve really enjoyed it and even signed up for the paid sync service. I blame my sister Jen for this, because she’s the one who got me started with bullet journals. I journaled on paper for a few years,…