Converting from Goodreads to Obsidian

Last month I got an idea that I'd like to do book reviews in my Obsidian note taking vault. This would satisfy a few problems I've had:
- I'd like to keep all of my book reviews private.
- I'd like to link to these books and ideas in them from other places inside my Obsidian vault.
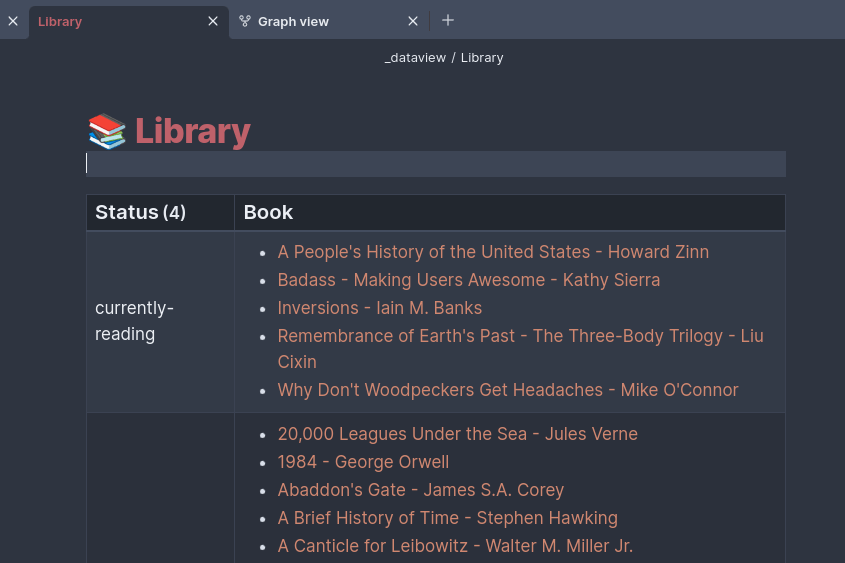
There were GREAT plugins available like the Obsidian Book Search plugin. However, there wasn't anything that would take my 400+ books with review text, rating, date read, and other info and convert that into markdown files for my Obsidian vault.
That's where my Goodreads to Obsidian converter comes in! If you're thinking of leaving Goodreads and doing all of your book reviews locally, then maybe this is for you.
The idea is relatively straightforward I hope.
- Take an export of all your books from Goodreads into a CSV file.
- Convert this CSV file into a number of markdown files (1 per book)
The execution was NOT so straightforward. I had to learn some Python code and handle lots of special cases. Subtitles, titles, series names, series numbers, special characters, this stuff is all over the place in a library of 400 books. That means I needed to build functions to parse all this data and take reasonable steps. I EVEN had to give the user some options to customize the behavior through arguments and run-time input.
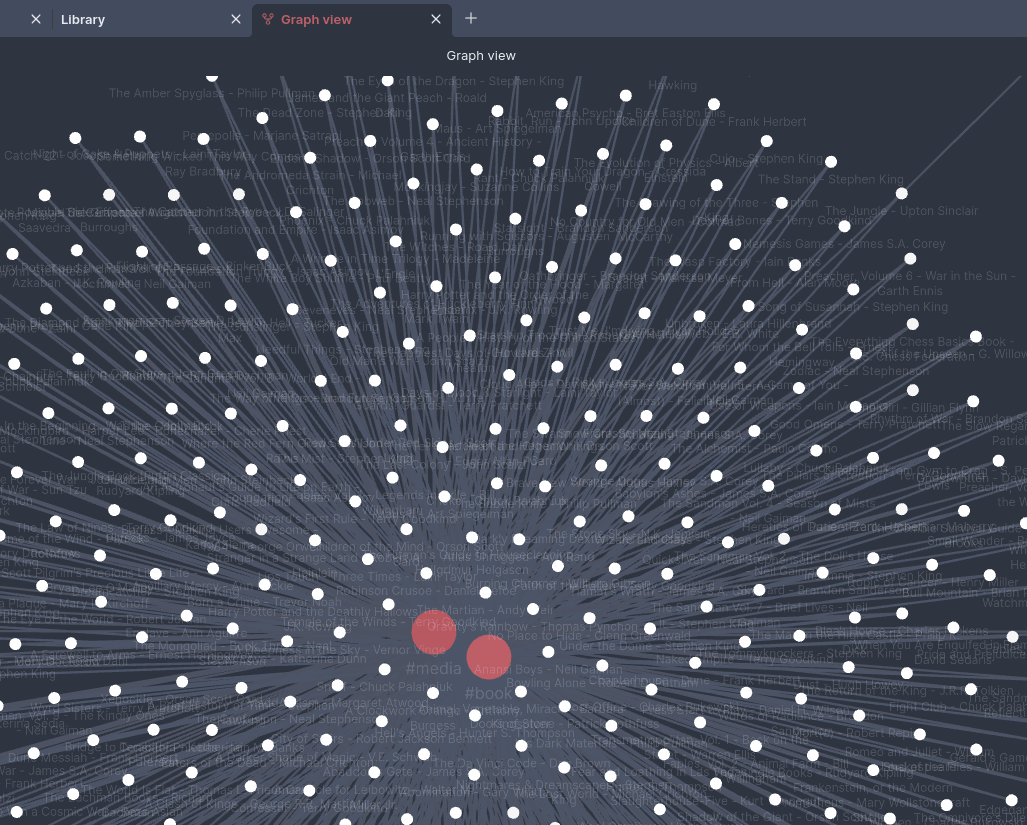
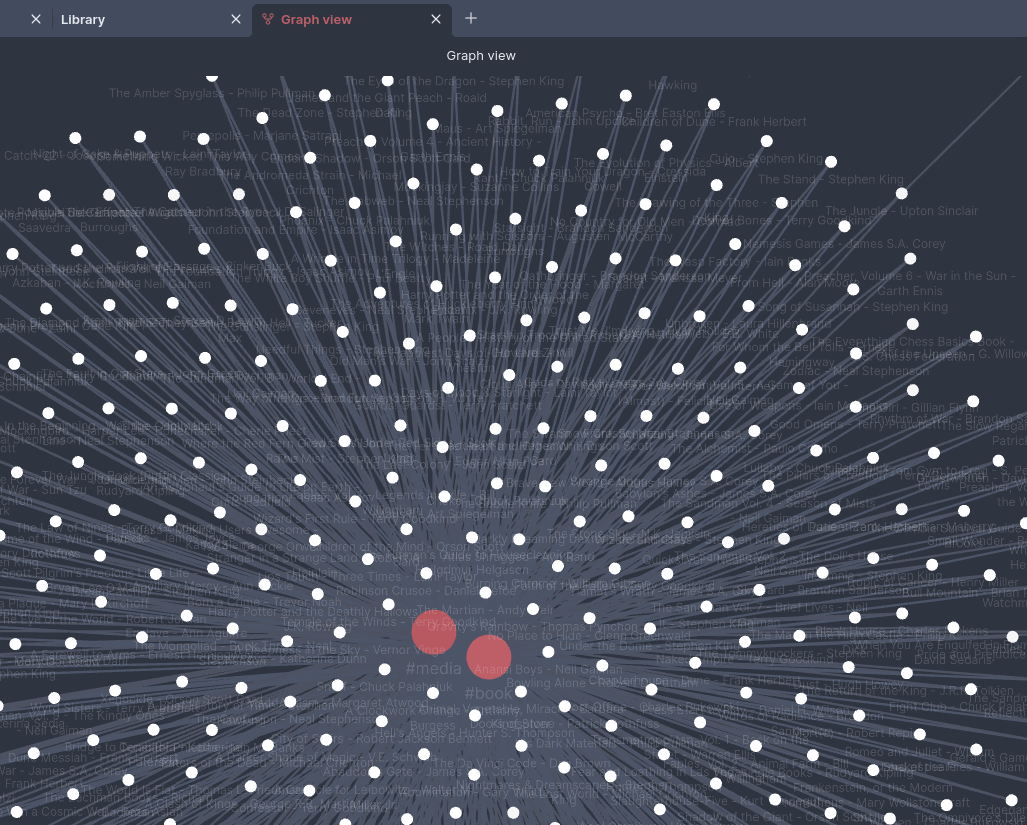
Today I did the import, and it works. I now have 400+ books as notes in my Obsidian vault. Will I regret this? Only time will tell. It was a great way to spend some nights and weekends tinkering on code though!
To give you an idea of what you're in for, here's what the code looks like when you run the help command.
user@host$ python3 csv-to-md.py -h
usage: csv-to-md.py [-h] [--template TEMPLATE] [--out OUT] [--sub_len SUB_LEN] [--dry] [--alias] csv
positional arguments:
csv Goodreads CSV export file to import
options:
-h, --help show this help message and exit
--template TEMPLATE Book Markdown template file with $variables. Uses book.md.Template by default.
--out OUT Output directory. Uses current dir as default.
--sub_len SUB_LEN Subtitle length for file name. 0 = none (default). a = ALL subtitle words. 1+ = num words long. c = custom
--dry If passed, perform a dry run and skip the file write steps.
--alias Add the base title as frontmatter alias when subtitle exists.Subtitle Length and Series
Edited 2023-07-15
The subtitle length, or sub_len feature probably took me the longest to figure out after Series.
Given a simple title and author, you could save your markdown note files as "Title - Author.md". This worked great for about 70% of the books in my library. The other 30% were tricky. Here are some examples that really tripped me up:
Naively - they should all be like this:
Book Title (Series Name, #1)
Transform the title, series name, and number into your frontmatter fields and you're on your way to a beautiful data structure!
But, this might be harder than I thought:
Guards! Guards! (Discworld, #8; City Watch, #1) # TWO SERIES!
Auberon (The Expanse, #8.5) # Floating point series!
Edgedancer (The Stormlight Archive #2.5) # Where is your comma?
Remembrance of Earth's Past: The Three-Body Trilogy (Remembrance of Earth's Past #1-3) # Subtitle and dashed series 1-3?
The System of the World (The Baroque Cycle, Vol. 3, Book 3) # Come on.
So I solved the series problem with regex to account for only those cases above, and I just look for the first series name, and number, and I'm pretty forgiving and shove just about anything into those fields. Dashes, points, whatever. If you have books with OTHER sorts of series formatting this script might not populate the series for you. Let me know some examples if this happens.
Here's an example from the above where I put the discovered fields into the series.
---
tags: book, media
publish: false
title: "Auberon"
aliases: ""
series:
series_name: The Expanse
series_num: 8.5
author: [James S.A. Corey]
status: read
isbn:
isbn13:
category:
rating: 0
read_count: 1
binding: Kindle Edition
num_pages: 78
pub_date: 2019
cover:
date_start: 2020-08-16
date_end: 2020-08-30
created:
modified:
---Next was dealing with subtitles in the file name. Let's take a few books as examples:
America (The Book): A Citizen's Guide to Democracy Inaction (Teacher's Edition) - Jon Stewart
This file name is too long! I want it to just be: "America (The Book) - Jon Stewart.md". I could strip the title at the first colon. That would be --sub_len 0, or zero words from the subtitle transferred into the file name.
But if we do subtitle length of zero, what happens to these two books?
The Mongoliad: Book Two - Neal Stephenson
The Mongoliad: Book Three - Neal Stephenson
They have a name collision! You'll wind up with two books that are written to the same file: "The Mongoliad - Neal Stephenson.md".
You could pass a length of two words (or a for all) for these books, but what about the 100 other books?
My solution to this problem was to introduce a CUSTOM subtitle length, or "c".
When you pass --sub_len c, the program will pause whenever a colon is detected in the title and ask you how many words you want to keep from the subtitle for the file name. Your options are:
- 0: zero words from the subtitle. Strip everything past the first colon.
- 1-N: 1-N words from the subtitle. Keep 1-N words past the colon.
- a: All, or everything from the subtitle. Keep it all except the colon itself.
I did this for my library and in practice I used either '0' or 'a', and never used anything else.
The purpose of all of the above was just to have nice and neat file names and avoid file name collisions. But we have just introduced ANOTHER problem. If we discard the subtitle in the file name, we lose some information. If we keep the long title in the file name we have a note that's awkward to link to in Obsidian. That's where the --alias command comes in.
When you choose --alias, we'll take the short title (everything before the first colon) and stick that in the aliases frontmatter. Here's "America (The Book)" to show what this looks like. The long title always goes in title. The file name is controlled by sub_len.
"America (The Book) - Jon Stewart.md"
---
tags: book, media
publish: false
title: "America (The Book): A Citizen's Guide to Democracy Inaction (Teacher's Edition)"
aliases: "America (The Book)"
series:
series_name:
series_num:
author: [Jon Stewart]
status: read
isbn: 0446691860
isbn13: 9780446691864
category:
rating: 0
read_count: 1
binding: Paperback
num_pages: 227
pub_date: 2006
cover:
date_start: 2011-02-10
date_end:
created:
modified:
---I did this so I don't lose the full title, and I also have the option to link to this book by the shorter alias in Obsidian.
To summarize, there are three different pieces of information:
- The file name which MUST be unique, and should be relatively short and without colons. Roughly, "Title - [Short Sub -] Author.md"
- Controlled by sub_len argument
- The full book title which we want to preserved in the frontmatter.
- Always present in title
- A short title alias in the frontmatter that we would like to be able to link to from other places inside our vault.
- Added if passing alias flag and the book has a subtitle
This is not a perfect solution, but with this approach all of your books should import. You might have to do some alias or file name tweaking here and there for corner cases.
Probably my biggest take away is that if I ever write multiple books I will be more careful with my titles and subtitles to avoid overlap! ;)