Tag: Work
-
Nutanix .NEXT Announcement – Acropolis and KVM
I’m happy to see that Nutanix has officially announced their upcoming strategic direction at the .NEXT conference. Using Nutanix Acropolis, KVM, and Prism – data center administrators now have the ability to truly make infrastructure invisible. What Is It? To read more about the specific details take a look at Andre Leibovici’s post here, then come back.…
-

Vienna Avaya Technology Forum
Part of my role on the Nutanix Performance and Solutions team is to “evangelize” the technology and tell the world about all the great work we’re doing writing documents, testing products and solutions, and assisting with customer engagements. The physical manifestation of that is me sitting in an airport typing up this blog post, on…
-
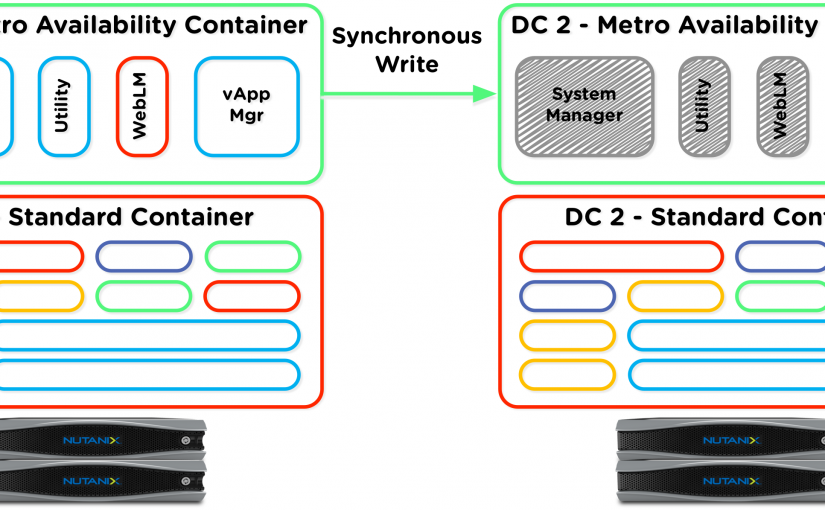
Survivable UC – Avaya Aura and Nutanix Data Protection
I wanted to share a bit of cool “value add” today, as my sales and marketing guys would call it. This is just one of the things for Avaya Aura and UC in general that a Nutanix deployment can bring to the table. Nutanix has the concept of Protection Domains and Metro Availability that have been…
-

Virtualized Avaya Aura on Nutanix – In Progress
The Avaya Technology Forum in Orlando was a great success! Thanks to everyone who attended and showed interest in Nutanix by stopping at the booth. I met a lot of interested potential customers and partners and was also able to learn more about what people are virtualizing these days. There is nothing quite like asking…
-
Nutanix and The 2015 Avaya Technology Forum
I’m at the 2015 Avaya Technology Forum with Nutanix to talk about Avaya Unified Communications on the Nutanix platform. Stop by the Nutanix and CRI booth to see the Nutanix gear in action. Nutanix 3460 and 1450 nodes will be powering all the demos you see for Avaya Aura and other applications! I’ve been testing…
-
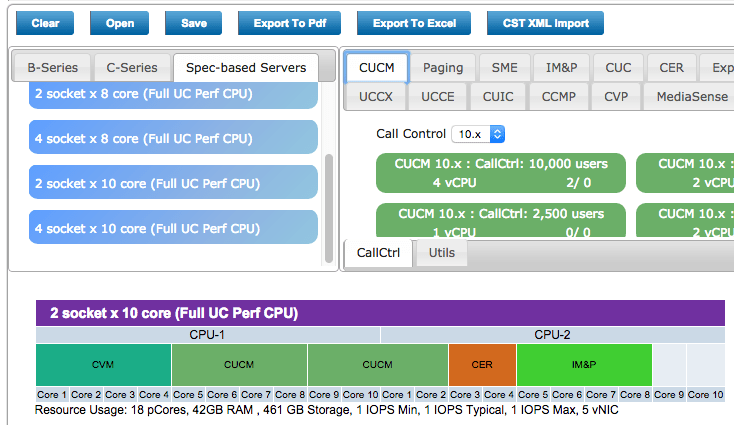
Nutanix and UC – Part 4: VM Placement and System Sizing
In the last blog post I talked about sizing individual VMs. Today we’ll look at placing UC VMs onto a Nutanix node (an ESXi host) and coming up with overall system sizing. First I’d like to announce the publication of my document for Virtualizing Cisco UC on Nutanix. Readers of the blog will recognize the content…
-
Nutanix and UC – Part 3: Cisco UC on Nutanix
In the previous posts we covered an Introduction to Cisco UC and Nutanix as well as Cisco’s requirements for UC virtualization. To quickly summarize… Nutanix is a virtualization platform that provides compute and storage in a way that is fault tolerant and scalable. Cisco UC provides a VMware centric virtualized VoIP collaboration suite that allows clients…
-
Nutanix and UC – Part 2: Cisco Virtualization Requirements
In the last post I covered an Introduction to Cisco UC and Nutanix. In this post I’ll cover UC performance and virtualization requirements. A scary part of virtualizing Cisco Unified Communications is worrying about being fully supported by Cisco TAC if a non-standard deployment path is chosen. This is due to a long history of…
-
Nutanix and UC – Part 1: Introduction and Overview
I’ll be publishing a series of blog posts outlining Cisco Unified Communications on Nutanix. At the end of this series I hope to have addressed any potential concerns running Cisco UC and Nutanix and provided all the tools for a successful deployment. Your comments are welcome and encouraged. Let’s start at the beginning, a very good…
-
Nutanix and Unified Communications
The past week has been a whirlwind of studying, research, and introductions now that I’ve started at Nutanix! I’m happy to be on the team working on Reference Architectures for Unified Communications. I’m planning to investigate the major Unified Communications platforms (VoIP, Voice Messaging, IM & Presence, E911) from the top vendors and come up…